The hypergeometric distribution describes the number of white balls in a sample of  balls draw without replacement from an urn with
balls draw without replacement from an urn with  white balls and
white balls and  black balls. The probability of having
black balls. The probability of having  white balls in the sample is:
white balls in the sample is:

This is because there are  possible ways to sample balls from the urn which has
possible ways to sample balls from the urn which has  black balls in total. Of these possibilities, there are
black balls in total. Of these possibilities, there are  ways of selecting exactly white balls.
ways of selecting exactly white balls.
The multivariate hypergeometric distribution is a generalization of the hypergeometric distribution. In the multivariate hypergeometric distribution, there are  colours instead of
colours instead of  . Suppose that the urn contains
. Suppose that the urn contains 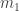 balls of the first colour,
balls of the first colour, 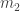 balls of the second colour and so on. The total number of balls in the urn is
balls of the second colour and so on. The total number of balls in the urn is  . Next we draw balls from the urn. Let
. Next we draw balls from the urn. Let  be the number of balls of colour
be the number of balls of colour  in our sample. The vector
in our sample. The vector  follows the multivariate hypergeometric distribution. The vector
follows the multivariate hypergeometric distribution. The vector  satisfies the constraints
satisfies the constraints  and
and  . The probability of observing
. The probability of observing 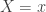 is
is

This is because there are  possible ways of sampling balls from the urn that has
possible ways of sampling balls from the urn that has  balls in total. Likewise, The number of ways of choosing
balls in total. Likewise, The number of ways of choosing  balls of colour
balls of colour 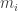 is
is  .
.
Sampling
There are two common methods for sampling from the multivariate hypergeometric distribution. The first option is to sample numbers from  without replacement. The numbers represent the balls in the urn. We can let
without replacement. The numbers represent the balls in the urn. We can let  represent the numbers with colour 1, and let
represent the numbers with colour 1, and let  represent the numbers with colour 2 and so on. Suppose that
represent the numbers with colour 2 and so on. Suppose that  is the sample of size without replacement from . Next define:
is the sample of size without replacement from . Next define:

Then the vector  will be distributed according to the multivariate hypergeometric distribution. This method of sampling has complexity on the order of
will be distributed according to the multivariate hypergeometric distribution. This method of sampling has complexity on the order of  . This is because sampling a random number of size has complexity
. This is because sampling a random number of size has complexity  and we need to sample of these numbers.
and we need to sample of these numbers.
There is a second method of sampling that is more efficient when is large and is small. This is a sequential method that samples each from a (univariate) hypergeometric distribution. The idea is that when sampling  we can treat the balls of colour
we can treat the balls of colour  as “white” and all the other colours as “black”. This means that marginally, is hypergeometric with parameters
as “white” and all the other colours as “black”. This means that marginally, is hypergeometric with parameters  and
and  and
and  . Furthermore, conditional on , the second entry,
. Furthermore, conditional on , the second entry,  , is also hypergeometric. The parameters for are
, is also hypergeometric. The parameters for are  ,
,  and
and  . In fact, all of the conditionals of are hypergeometric random variables and so can sampled sequentially. The python code at the end of this post implements the sequential sampler.
. In fact, all of the conditionals of are hypergeometric random variables and so can sampled sequentially. The python code at the end of this post implements the sequential sampler.
The complexity of the sequential method is bounded above by times the complexity of sampling from the hypergeometric distribution. By using the ratio of uniform distribution this can be done in complexity on the order of  . The overall complexity of the sequential method is therefore on the order of
. The overall complexity of the sequential method is therefore on the order of  which can be much smaller than .
which can be much smaller than .
import numpy as np
def multivariate_hypergeometric_sample(m, n):
x = np.zeros_like(m)
k = len(m)
for i in range(k-1):
x[i] = np.random.hypergeometric(m[i], np.sum(m[(i+1):]), n)
n -= x[i]
x[k-1] = n
return x
