The discrete Fourier transform (DFT) is a mapping from 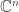 to . Given a vector
to . Given a vector  , the discrete Fourier transform of
, the discrete Fourier transform of  is another vector
is another vector  given by,
given by,

If we let  , then
, then  can be written more compactly as
can be written more compactly as

The map from to is linear and can therefor be represented as multiplication by an  matrix
matrix  . Looking at the equation above, we can see that if we set
. Looking at the equation above, we can see that if we set  and use
and use  -indexing, then,
-indexing, then,

This suggests that calculating the vector  would require roughly
would require roughly  operations. However, the famous fast Fourier transform shows that can be computed in roughly
operations. However, the famous fast Fourier transform shows that can be computed in roughly  operations. There are many derivations of the fast Fourier transform but I wanted to focus on one which is based on factorizing the matrix into sparse matrices.
operations. There are many derivations of the fast Fourier transform but I wanted to focus on one which is based on factorizing the matrix into sparse matrices.
Matrix factorizations
A factorization of a matrix  is a way of writing as a product of matrices
is a way of writing as a product of matrices  where typically
where typically  is
is  or
or  . Matrix factorizations can tell us information about the matrix . For example, the singular value decomposition tells us the spectral norm and singular vectors (and lots more). Other matrix factorizations can help us compute things related to the matrix . The QR decomposition helps us solve least-squares problems and the LU factorization let us invert in (almost) the same amount of time it takes to solve the equation
. Matrix factorizations can tell us information about the matrix . For example, the singular value decomposition tells us the spectral norm and singular vectors (and lots more). Other matrix factorizations can help us compute things related to the matrix . The QR decomposition helps us solve least-squares problems and the LU factorization let us invert in (almost) the same amount of time it takes to solve the equation 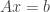 .
.
Each of the factorizations above applied to arbitrary matrices. Every possible matrix has an singular value decomposition and a QR factorization. Likewise all square matrices have an LU factorization. The DFT matrix has a factorization which most matrices other matrices do not. This factorization lets us write  where each matrix
where each matrix 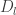 is sparse.
is sparse.
Sparse matrices
A matrix is sparse if many of the entries of are zero. There isn’t a precise definition of “many”. A good heuristic is that if has size  by
by  , then is sparse if the number of non-zero entries is of the order or . In contrast, a dense matrix is one where the number of non-zero entries is of the same order of
, then is sparse if the number of non-zero entries is of the order or . In contrast, a dense matrix is one where the number of non-zero entries is of the same order of 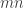 .
.
The structure of sparse matrices makes them especially nice to work with. They take up a lot less memory and they are quicker to compute with. If  has only
has only  non-zero elements, then for any vector
non-zero elements, then for any vector  , the matrix-vector product
, the matrix-vector product 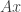 can be computed in order operations. If is much less than , then this can be a huge speed up.
can be computed in order operations. If is much less than , then this can be a huge speed up.
This shows why a sparse factorization of the DFT matrix will give a fast way of calculating  . Specifically, suppose that we have
. Specifically, suppose that we have  and each matrix has just
and each matrix has just  non-zero entries. Then, for any vector , we can compute
non-zero entries. Then, for any vector , we can compute  in stages. First we multiply by
in stages. First we multiply by 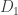 to produce
to produce  . The output is then multiplied by
. The output is then multiplied by 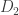 to produce
to produce  . We continue in this way until we finally multiply
. We continue in this way until we finally multiply  by
by  to produce
to produce  . The total computation cost is of the order
. The total computation cost is of the order  which can be drastically less than .
which can be drastically less than .
The DFT factorization
We’ll now show that does indeed have a sparse matrix factorization. To avoid some of the technicalities, we’ll assume that is a power of . That is,  for some . Remember that the discrete Fourier transform of is the vector given by
for some . Remember that the discrete Fourier transform of is the vector given by

where  . The idea behind the fast Fourier transform is to split the above sum into two terms. One where we add up the even values of
. The idea behind the fast Fourier transform is to split the above sum into two terms. One where we add up the even values of  and one where we add up the odd values of . Specifically,
and one where we add up the odd values of . Specifically,

We’ll now look at each of these sums separately. In the first sum, we have terms of the form  , these can by rewritten as follows,
, these can by rewritten as follows,
 .
.
We can also use this result to rewrite the terms  ,
,

If we plug both of these back into the expression for , we get

This shows that the Fourier transform of the -dimensional vector can be done by computing and combining the Fourier transforms of the  -dimensional vectors. One of these vectors contain the even indexed elements of and the others contain the odd indexed elements of .
-dimensional vectors. One of these vectors contain the even indexed elements of and the others contain the odd indexed elements of .
There is one more observation that we need. If is between and  , then we can simplify the above expression for
, then we can simplify the above expression for 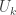 . Specifically, if we set
. Specifically, if we set  , then
, then

If we plug this into the above formula for , then we get
 for
for  .
.
This reduces the computation since there are some computations we only have to do once but can use twice. The algebra we did above shows that we can compute the discrete Fourier transform of in the following step.
- Form the vectors
 and
and  .
.
- Calculate the discrete Fourier transforms of
 and
and  . This gives two vector
. This gives two vector  .
.
- Compute by,

The steps above break down computing  into three simpler steps. Each of these simpler steps are also linear maps and can therefore be written as multiplication by a matrix. If we call these matrices
into three simpler steps. Each of these simpler steps are also linear maps and can therefore be written as multiplication by a matrix. If we call these matrices 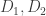 and
and 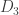 , then
, then
- The matrix maps to
 . That is
. That is

- The matrix is block-diagonal and each block is the -dimensional discrete Fourier transformation matrix. That is

where  is given by
is given by  .
.
- The matrix combines two -vectors according to the formula in step 3 above,

The three-step procedure above for calculating is equivalent to iteratively multiplying by , then and the finally by . Another way of saying this is that  is a matrix factorization!
is a matrix factorization!
From the definitions, we can see that each of the matrices and have a lot of zeros. Specifically, has just non-zero entries (one in each row), has  non-zero entries (two blocks of
non-zero entries (two blocks of  non-zeros) and has
non-zeros) and has  non-zero entries (two in each row). This means that the product
non-zero entries (two in each row). This means that the product  can be computed in roughly
can be computed in roughly

operations. This is far away from the operations promised at the start of this blog post. However, the matrix contains two copies of the discrete Fourier transform matrix. This means we could apply the exact same argument to the matrix . This lets us replace  with
with  . This brings the number of operations down to
. This brings the number of operations down to

We can again keep going! If we recall that  , then we get to repeat the proccess times in total giving approximately,
, then we get to repeat the proccess times in total giving approximately,
 operations.
operations.
So by using lots of sparse matrices, we can compute in  operations instead of
operations instead of  operations.
operations.
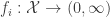

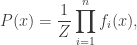

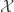


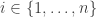
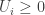
![\displaystyle{P(U \mid X) = \prod_{i=1}^n \mathrm{Unif}[0,f_i(X)]}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7BP%28U+%5Cmid+X%29+%3D+%5Cprod_%7Bi%3D1%7D%5En+%5Cmathrm%7BUnif%7D%5B0%2Cf_i%28X%29%5D%7D.&bg=ffffff&fg=333333&s=0&c=20201002)



![[0,f_i(X)]](https://s0.wp.com/latex.php?latex=%5B0%2Cf_i%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![\displaystyle{P(X,U) =P(X)P(U\mid X)\propto \prod_{i=1}^n f_i(X) \frac{1}{f_i(X)} I[U_i \le f(X_i)] = \prod_{i=1}^n I[U_i \le f(X_i)]}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7BP%28X%2CU%29+%3DP%28X%29P%28U%5Cmid+X%29%5Cpropto++%5Cprod_%7Bi%3D1%7D%5En+f_i%28X%29+%5Cfrac%7B1%7D%7Bf_i%28X%29%7D+I%5BU_i+%5Cle+f%28X_i%29%5D+%3D+%5Cprod_%7Bi%3D1%7D%5En+I%5BU_i+%5Cle+f%28X_i%29%5D%7D.&bg=ffffff&fg=333333&s=0&c=20201002)




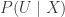
.
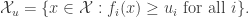

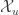
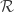


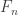 is the
is the  and
and  for
for 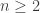 . Ron’s infinite series can be proved using the recurrence relation for the Fibonacci numbers and the general result is that for any
. Ron’s infinite series can be proved using the recurrence relation for the Fibonacci numbers and the general result is that for any 

 so the sum does converge for
so the sum does converge for  . Let
. Let  be the value of the sum. If we multiply
be the value of the sum. If we multiply 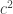 , then we get
, then we get
 and
and  .
.  and so
and so
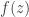 given by
given by
 , then by Ron’s exercise
, then by Ron’s exercise
 . So solving Ron’s exercise is equivalent to finding the generating function of the Fibonacci numbers!
. So solving Ron’s exercise is equivalent to finding the generating function of the Fibonacci numbers! . I leave this sum for another blog post!
. I leave this sum for another blog post!
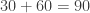 mph. Jack reaches Joe in 10 minutes which is one sixth of an hour. This means that the initial distance between them must have been
mph. Jack reaches Joe in 10 minutes which is one sixth of an hour. This means that the initial distance between them must have been 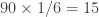 miles.
miles. 
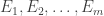 , each of which occur with probability
, each of which occur with probability 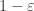 . The event that all of the
. The event that all of the 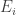 occur is
occur is  . By using independence we can calculate the probability of
. By using independence we can calculate the probability of  ,
,
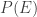 by using the union bound. This gives,
by using the union bound. This gives,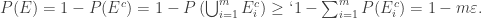
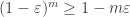 . This is an instance of
. This is an instance of 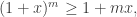
 and
and  . This inequality states the red line is always underneath the black curve in the below picture. For an interactive version of this graph where you can change the value of
. This inequality states the red line is always underneath the black curve in the below picture. For an interactive version of this graph where you can change the value of 
 is between
is between  and
and 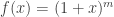 is convex on the set
is convex on the set  . The function
. The function 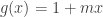 is the tangent line of this function at the point
is the tangent line of this function at the point 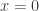 . Convexity of
. Convexity of  means that the graph of
means that the graph of 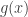 . This tells us that
. This tells us that 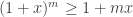 .
.  , the function
, the function 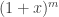 is no longer convex but actually concave and the inequality reverses. For
is no longer convex but actually concave and the inequality reverses. For 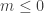 ,
, 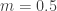 and the red line is above the black one. In the second picture
and the red line is above the black one. In the second picture  and the black line is back on top.
and the black line is back on top.

 invertible matrix and
invertible matrix and  is a length
is a length 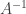 and solving the equation
and solving the equation 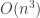 floating point operations (flops). This surprised me because naively computing the columns of
floating point operations (flops). This surprised me because naively computing the columns of 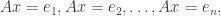
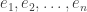 are the standard basis vectors. I thought this would mean that calculating
are the standard basis vectors. I thought this would mean that calculating 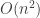 flops. Now to solve
flops. Now to solve  , we can simply factor
, we can simply factor  . Inverting the matrix requires the same order of flops as a single solve!
. Inverting the matrix requires the same order of flops as a single solve! that describes how the states change after interaction. Specifically, if the first particle is in state
that describes how the states change after interaction. Specifically, if the first particle is in state  , then their states after interacting will be
, then their states after interacting will be
 are the components of
are the components of  . Recall that the particles move past each other when they interact. Thus, to keep track of the whole system we need an element of
. Recall that the particles move past each other when they interact. Thus, to keep track of the whole system we need an element of  to keep track of the states and a permutation
to keep track of the states and a permutation 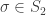 to keep track of the positions.
to keep track of the positions. . As before, each particle has a state in
. As before, each particle has a state in  . The particles also have a position which is described by a permutation
. The particles also have a position which is described by a permutation  . The order the entries of
. The order the entries of 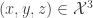 corresponds to the labels of the particles not their positions. A possible configuration is shown below:
corresponds to the labels of the particles not their positions. A possible configuration is shown below: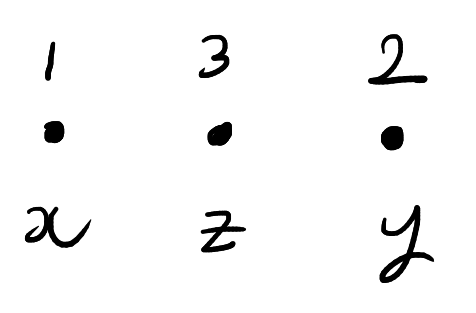
 .
.
 and the permutation
and the permutation  .
. . The function
. The function  is given by applying
is given by applying 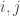 coordinates of
coordinates of 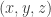 and acting by the identity on the remaining coordinate. In symbols,
and acting by the identity on the remaining coordinate. In symbols,


 and
and  and states
and states 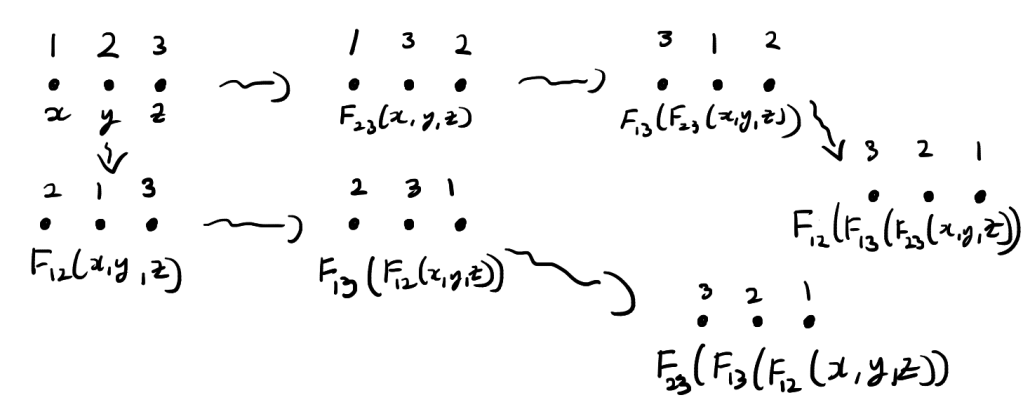


 . The function
. The function 
 .
. commute, then the function
commute, then the function  is a solution the Yang-Baxter equation.
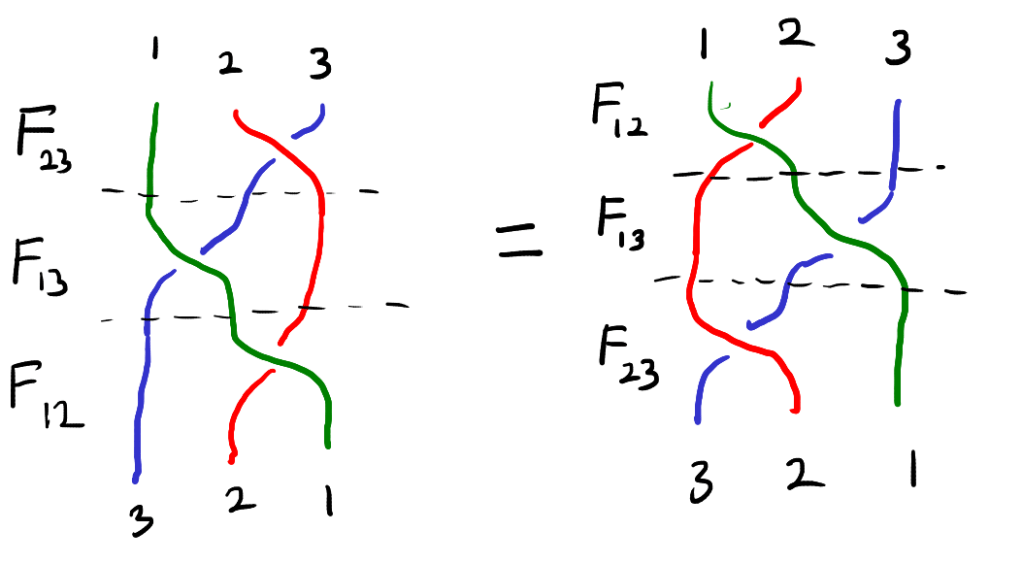
is a solution the Yang-Baxter equation. -norm of a vector
-norm of a vector  is defined to be:
is defined to be:
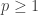 , then the
, then the 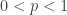 , this function is not convex and actually concave when all the entries of
, this function is not convex and actually concave when all the entries of 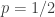 . In this special case, the mathematics simplifies nicely.
. In this special case, the mathematics simplifies nicely.

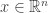 with
with 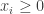 for all
for all 
 is concave when
is concave when  . This can be proved by calculating the Hessian of this function and verifying that it is negative semi-definite.
. This can be proved by calculating the Hessian of this function and verifying that it is negative semi-definite. is also concave. This is because
is also concave. This is because  is concave.
is concave. is defined on pairs of probability distributions
is defined on pairs of probability distributions  on a common set
on a common set  . For such a pair,
. For such a pair,

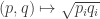 is concave and so the negative sum of such functions is convex. Thus,
is concave and so the negative sum of such functions is convex. Thus,  is convex.
is convex.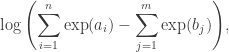
 . Such expressions can be difficult to evaluate directly since the exponentials can easily cause overflow errors. In this post, I’ll talk about a clever way to avoid such errors.
. Such expressions can be difficult to evaluate directly since the exponentials can easily cause overflow errors. In this post, I’ll talk about a clever way to avoid such errors.
 and use the identity
and use the identity
 for all
for all  , the left hand side of the above equation can be computed without the risk of overflow. To calculate,
, the left hand side of the above equation can be computed without the risk of overflow. To calculate,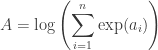 and
and 

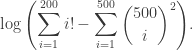
 . However, R has the functions
. However, R has the functions  and
and  for large values of
for large values of 
 but an unknown rate
but an unknown rate ![\rho \in [0,1]](https://s0.wp.com/latex.php?latex=%5Crho+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The rate
. The rate  is given a
is given a  prior. That is the prior distribution of
prior. That is the prior distribution of 
 is a normalizing constant. The model can thus be written as
is a normalizing constant. The model can thus be written as


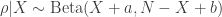 .
. . To calculate the distribution of
. To calculate the distribution of 


 for
for 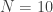 and a number of different values of
and a number of different values of  and
and 
