The Neyman-Pearson lemma is foundational and important result in the theory of hypothesis testing. When presented in class the proof seemed magical and I had no idea where the ideas came from. I even drew a face like this 😲 next to the usual  in my book when the proof was finished. Later in class we learnt the method of undetermined multipliers and suddenly I saw where the Neyman-Pearson lemma came from.
in my book when the proof was finished. Later in class we learnt the method of undetermined multipliers and suddenly I saw where the Neyman-Pearson lemma came from.
In this blog post, I’ll first give some background and set up notation for the Neyman-Pearson lemma. Then I’ll talk about the method of undetermined multipliers and show how it can be used to derive and prove the Neyman-Pearson lemma. Finally, I’ll write about why I still think the Neyman-Pearson lemma is magical despite the demystified proof.
Background
In the set up of the Neyman-Pearson lemma we have data  which is a realisation of some random variable
which is a realisation of some random variable  . We wish to conclude something about the distribution of from our data by doing a hypothesis test.
. We wish to conclude something about the distribution of from our data by doing a hypothesis test.
In the Neyman-Pearson lemma we have simple hypotheses. That is our data either comes from the distribution  or from the distribution
or from the distribution  . Thus, our null hypothesis is
. Thus, our null hypothesis is  and our alternative hypothesis is
and our alternative hypothesis is  .
.
A test of  against
against 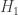 is a function
is a function  that takes in data and returns a number
that takes in data and returns a number ![\phi(x) \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cphi%28x%29+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The value
. The value 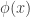 is the probability under the test of rejecting given the observed data . That is, if
is the probability under the test of rejecting given the observed data . That is, if  , we always reject and if
, we always reject and if 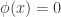 we never reject . For in-between values
we never reject . For in-between values 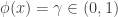 , we reject with probability
, we reject with probability  .
.
An ideal test would have two desirable properties. We would like a test that rejects with a low probability when is true but we would also like the test to reject with a high probability when is true. To state this more formally, let ![\mathbb{E}_0[\phi(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_0%5B%5Cphi%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![\mathbb{E}_1[\phi(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) be the expectation of
be the expectation of  under and respectively. The quantity is the probability we reject when is true. Likewise, the quantity is the probability we reject when is true. An optimal test would be one that minimises and maximises .
under and respectively. The quantity is the probability we reject when is true. Likewise, the quantity is the probability we reject when is true. An optimal test would be one that minimises and maximises .
Unfortunately the goals of minimising and maximising are at odds with one another. This is because we want to be small in order to minimise and we want to be large to maximise . In nearly all cases we have to trade off between these two goals and there is no single test that simultaneously achieves both.
To work around this, a standard approach is to focus on maximising while requiring that remains below some threshold. The quantity is called the power of the test . If  is a number between
is a number between  and
and  , we will say that has level– if
, we will say that has level– if ![\mathbb{E}_1[\phi(X)] \le \alpha](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D+%5Cle+%5Calpha&bg=ffffff&fg=333333&s=0&c=20201002) . A test is said to be most powerful at level-, if
. A test is said to be most powerful at level-, if
- The test is level-.
- For all level- tests
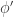 , the test is more powerful than . That is,
, the test is more powerful than . That is,
![\mathbb{E}_1[\phi'(X)] \le \mathbb{E}_1[\phi(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_1%5B%5Cphi%27%28X%29%5D+%5Cle+%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
Thus we can see that finding a most powerful level- test is a constrained optimisation problem. We wish to maximise the quantity
subject to the constraint
![\mathbb{E}_0[\phi(X)] \le \alpha](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_0%5B%5Cphi%28X%29%5D+%5Cle+%5Calpha&bg=ffffff&fg=333333&s=0&c=20201002)
With this in mind, we turn to the method of undetermined multipliers.
The method of undetermined multipliers
The method of undetermined multipliers (also called the method of Lagrange multipliers) is a very general optimisation tool. Suppose that we have a set  and two function
and two function 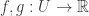 and we wish to maximise
and we wish to maximise 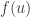 subject to the constraint
subject to the constraint 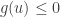 .
.
In the context of hypothesis testing, the set is the set of all tests . The objective function  is given by
is given by ![f(\phi) = \mathbb{E}_1[\phi(X)]](https://s0.wp.com/latex.php?latex=f%28%5Cphi%29+%3D+%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) . That is,
. That is,  is the power of the test . The constraint function
is the power of the test . The constraint function  is given by
is given by ![g(\phi)=\mathbb{E}_1[\phi(X)]-\alpha](https://s0.wp.com/latex.php?latex=g%28%5Cphi%29%3D%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D-%5Calpha&bg=ffffff&fg=333333&s=0&c=20201002) so that
so that  if and only if has level-.
if and only if has level-.
The method of undetermined multipliers allows us to reduce this constrained optimisation problem to a (hopefully easier) unconstrained optimisation problem. More specifically we have the following result:
Proposition: Suppose that  is such that:
is such that:
 ,
,- There exists
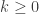 , such that
, such that 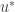 maximises
maximises 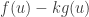 over all
over all  .
.
Then  maximises under the constraint .
maximises under the constraint .
Proof: Suppose that satisfies the above two dot points. We need to show that for all , if , then 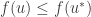 . By assumption we know that
. By assumption we know that  and maximises . Thus, for all ,
and maximises . Thus, for all ,
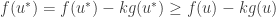 .
.
Now suppose . Then, 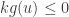 and so
and so  and so
and so 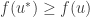 as needed.
as needed.
The constant  is the undetermined multiplier. The way to use the method of undetermined is to find values
is the undetermined multiplier. The way to use the method of undetermined is to find values  that maximise
that maximise 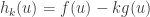 for each . The multiplier is then varied so that the constraint
for each . The multiplier is then varied so that the constraint  is satisfied.
is satisfied.
Proving the Neyman-Pearson lemma
Now let’s use the method of undetermined multipliers to find most powerful tests. Recall the set which we are optimising over is the set of all tests . Recall also that we wish to optimise subject to the constraint ![g(\phi) = \mathbb{E}_0[\phi(X)] - \alpha \le 0](https://s0.wp.com/latex.php?latex=g%28%5Cphi%29+%3D+%5Cmathbb%7BE%7D_0%5B%5Cphi%28X%29%5D+-+%5Calpha+%5Cle+0&bg=ffffff&fg=333333&s=0&c=20201002) . The method of undetermined multipliers says that we should consider maximising the function
. The method of undetermined multipliers says that we should consider maximising the function
![h_k(\phi) = \mathbb{E}_1[\phi(X)] - k\mathbb{E}_0[\phi(X)]](https://s0.wp.com/latex.php?latex=h_k%28%5Cphi%29+%3D+%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D+-+k%5Cmathbb%7BE%7D_0%5B%5Cphi%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,
where . Suppose that both and have densities1 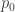 and
and 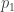 with respect to some measure
with respect to some measure  . We can we can write the above expectations as integrals. That is,
. We can we can write the above expectations as integrals. That is,
![\mathbb{E}_0[\phi(X)] = \int \phi(x)p_0(x)\mu(dx)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_0%5B%5Cphi%28X%29%5D+%3D+%5Cint+%5Cphi%28x%29p_0%28x%29%5Cmu%28dx%29&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![\mathbb{E}_1[\phi(X)] = \int \phi(x)p_1(x)\mu(dx)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D+%3D+%5Cint+%5Cphi%28x%29p_1%28x%29%5Cmu%28dx%29&bg=ffffff&fg=333333&s=0&c=20201002) .
.
Thus the function 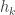 is equal to
is equal to
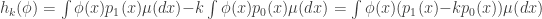 .
.
We now wish to maximise the function  . Recall that is a function that take values in
. Recall that is a function that take values in ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Thus, the integral
. Thus, the integral
 ,
,
is maximised if and only if  when
when  and when
and when  . Note that if and only if
. Note that if and only if 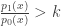 . Thus for each , a test
. Thus for each , a test 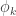 maximises if and only if
maximises if and only if

The method of undetermined multipliers says that if we can find so that the above is satisfied and  , then is a most powerful test. Recall that
, then is a most powerful test. Recall that  is equivalent to
is equivalent to ![\mathbb{E}_1[\phi(X)]=\alpha](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_1%5B%5Cphi%28X%29%5D%3D%5Calpha&bg=ffffff&fg=333333&s=0&c=20201002) . By summarising the above argument, we arrive at the Neyman-Pearson lemma,
. By summarising the above argument, we arrive at the Neyman-Pearson lemma,
Neyman-Pearson Lemma2: Suppose that is a test such that
then is most powerful at level- for testing against .
The magic of Neyman-Pearson
By learning about undetermined multipliers I’ve been able to better understand the proof of the Neyman-Pearson lemma. I now view it is as clever solution to a constrained optimisation problem rather than something that comes out of nowhere.
There is, however, a different aspect of Neyman-Pearson that continues to surprise me. This aspect is the usefulness of the lemma. At first glance the Neyman-Pearson lemma seems to be a very specialised result because it is about simple hypothesis testing. In reality most interesting hypothesis tests have composite nulls or composite alternatives or both. It turns out that Neyman-Pearson is still incredibly useful for composite testing. Through ideas like monotone likelihood ratios, least favourable distributions and unbiasedness, the Neyman-Pearson lemma or similar ideas can be used to find optimal tests in a variety of settings.
Thus I must admit that the title of this blog post is a little inaccurate and deceptive. I do believe that, given the tools of undetermined multipliers and the set up of simple hypothesis testing, one is naturally led to the Neyman-Pearson lemma. However, I don’t believe that many could have realised how useful and interesting simple hypothesis testing would be.
- The assumption that and have densities with respect to a common measure is not a restrictive assumption since one can always take
 and the apply Radon-Nikodym. However there is often a more natural choice of such as Lebesgue measure on
and the apply Radon-Nikodym. However there is often a more natural choice of such as Lebesgue measure on  or the counting measure on
or the counting measure on  .
. - What I call the Neyman-Pearson lemma is really only a third of the Neyman-Pearson lemma. There are two other parts. One that guarantees the existence of a most powerful test and one that is a partial converse to the statement in this post.



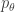




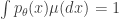

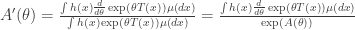


![A'(\theta) = \mathbb{E}_\theta[T(X)]](https://s0.wp.com/latex.php?latex=A%27%28%5Ctheta%29+%3D+%5Cmathbb%7BE%7D_%5Ctheta%5BT%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)




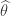

![A'(\widehat{\theta}) = \mathbb{E}_{\widehat{\theta}}[T(X)]](https://s0.wp.com/latex.php?latex=A%27%28%5Cwidehat%7B%5Ctheta%7D%29+%3D+%5Cmathbb%7BE%7D_%7B%5Cwidehat%7B%5Ctheta%7D%7D%5BT%28X%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}_{\widehat{\theta}}[T(X)] = \frac{1}{n}\sum_{i=1}^n T(X_i)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5Cwidehat%7B%5Ctheta%7D%7D%5BT%28X%29%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+T%28X_i%29&bg=ffffff&fg=333333&s=0&c=20201002)

![[0,\theta]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Ctheta%5D&bg=ffffff&fg=333333&s=0&c=20201002)
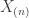


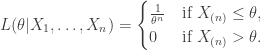



![\mathbb{E}_\theta[X_{(n)}] = \theta \frac{n}{n+1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Ctheta%5BX_%7B%28n%29%7D%5D++%3D+++%5Ctheta+%5Cfrac%7Bn%7D%7Bn%2B1%7D&bg=ffffff&fg=333333&s=0&c=20201002)
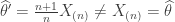
![\mathbb{E}_0[\phi(X)] = \alpha](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_0%5B%5Cphi%28X%29%5D+%3D+%5Calpha&bg=ffffff&fg=333333&s=0&c=20201002) , and
, and

 data points
data points  where
where  is a vector in
is a vector in  is a number in
is a number in  . We model
. We model  , where
, where 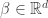 is a unknown vector of coefficients and
is a unknown vector of coefficients and  is a random variable with mean
is a random variable with mean  . We also require that for
. We also require that for  , the random variable
, the random variable 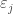 .
.  to be the vector with entries
to be the vector with entries  , that is
, that is  and
and 

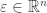 is a random vector with mean
is a random vector with mean  . To simplify calculations we will assume that
. To simplify calculations we will assume that  where
where 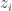 is a number. The values
is a number. The values  which contains the coefficients of our model. That is, given a sample
which contains the coefficients of our model. That is, given a sample  , we wish to construct a vector
, we wish to construct a vector  which approximates the true parameter
which approximates the true parameter 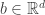 that minimizes the quantity
that minimizes the quantity  .
. and setting the derivative equal to
and setting the derivative equal to 
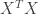 is invertible. In this case then the normal equations have a unique solution
is invertible. In this case then the normal equations have a unique solution  .
.  we would use
we would use 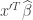 to predict the corresponding value of
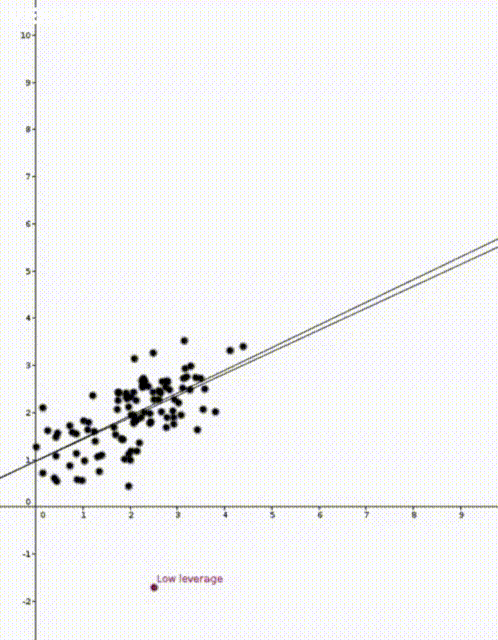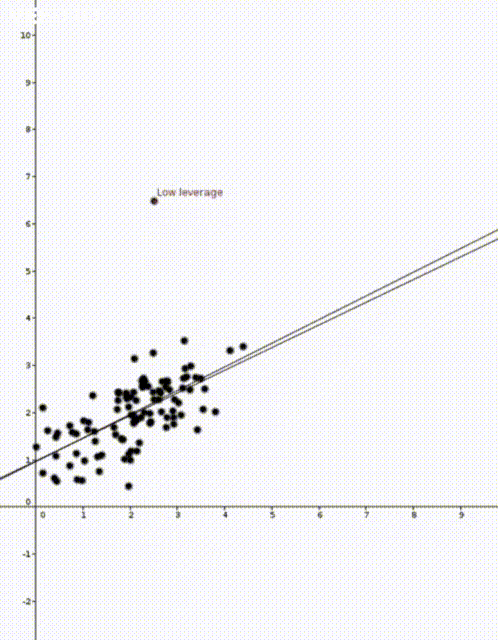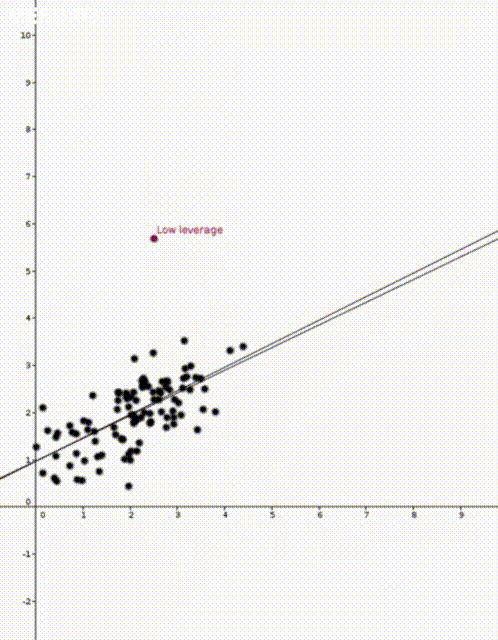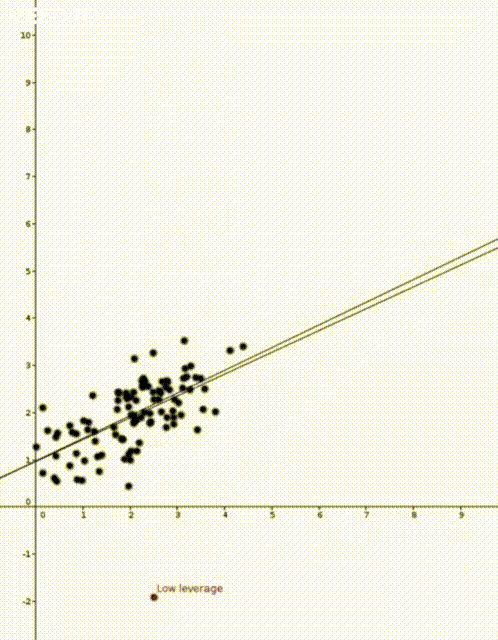
to predict the corresponding value of 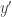 . This was how the straight lines in the two animations were calculated.
. This was how the straight lines in the two animations were calculated.  . Note that
. Note that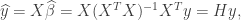
 is called the hat matrix for the model (since it puts the hat
is called the hat matrix for the model (since it puts the hat 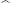 on
on 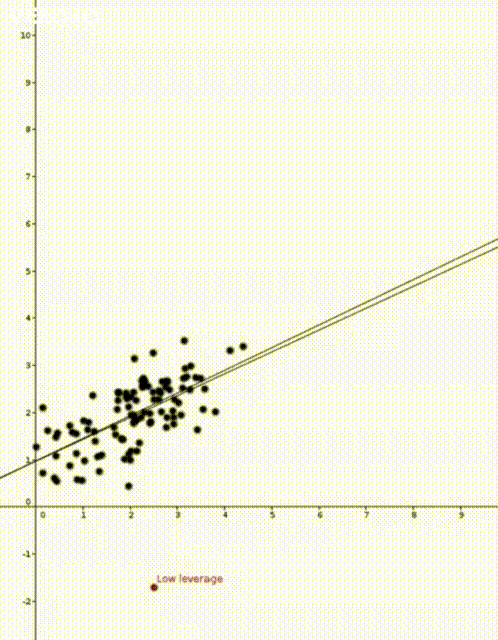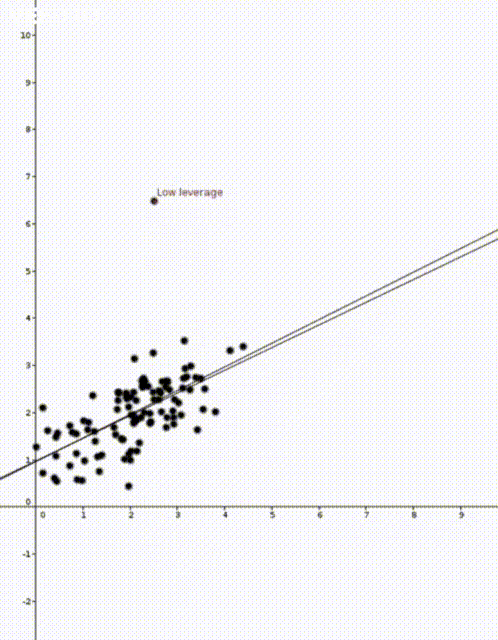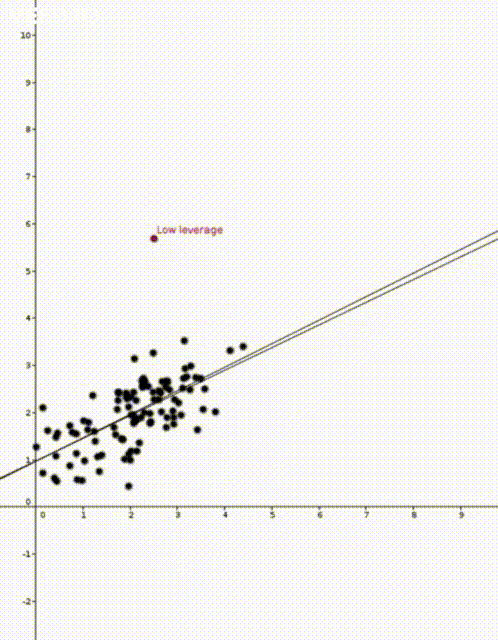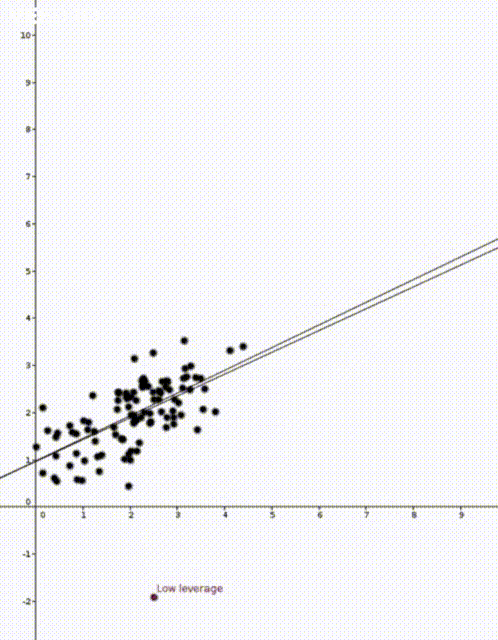

 That is, the leverage score tells us how much does the prediction
That is, the leverage score tells us how much does the prediction  change if we change
change if we change  , the leverage score of
, the leverage score of  , the
, the 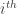 diagonal element of the hat matrix
diagonal element of the hat matrix  . The idea is that if a data point
. The idea is that if a data point 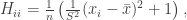
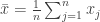 is the sample mean and
is the sample mean and  is the sample variance. Thus high leverage scores correspond to points that are far away from the centre of our data
is the sample variance. Thus high leverage scores correspond to points that are far away from the centre of our data 