This post is an introduction to the negative binomial distribution and a discussion of different ways of approximating the negative binomial distribution.
The negative binomial distribution describes the number of times a coin lands on tails before a certain number of heads are recorded. The distribution depends on two parameters 


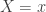



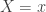

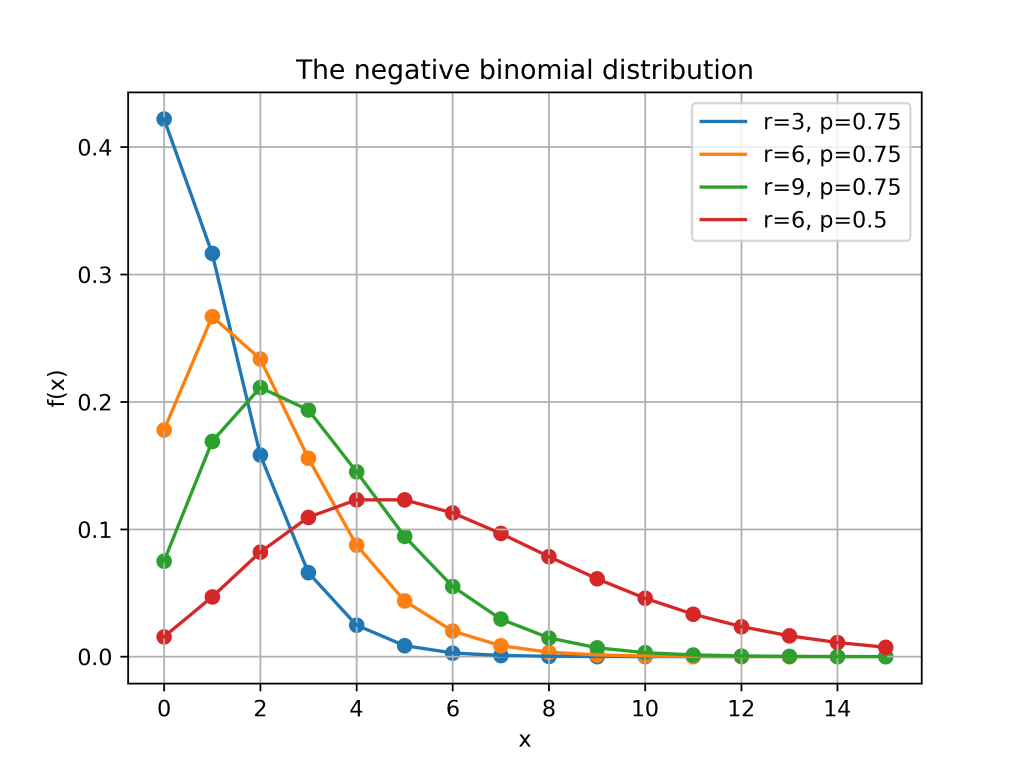
Here is a plot of the function 
Poisson approximations
When the parameter 




Total variation distance is a common way to measure the distance between two discrete probability distributions. The log-log plot below shows that the error from the Poisson approximation is on the order of 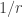


It turns out that is is possible to get a more accurate approximation by using a different Poisson distribution. In the first approximation, we used a Poisson random variable with mean 


The change from 
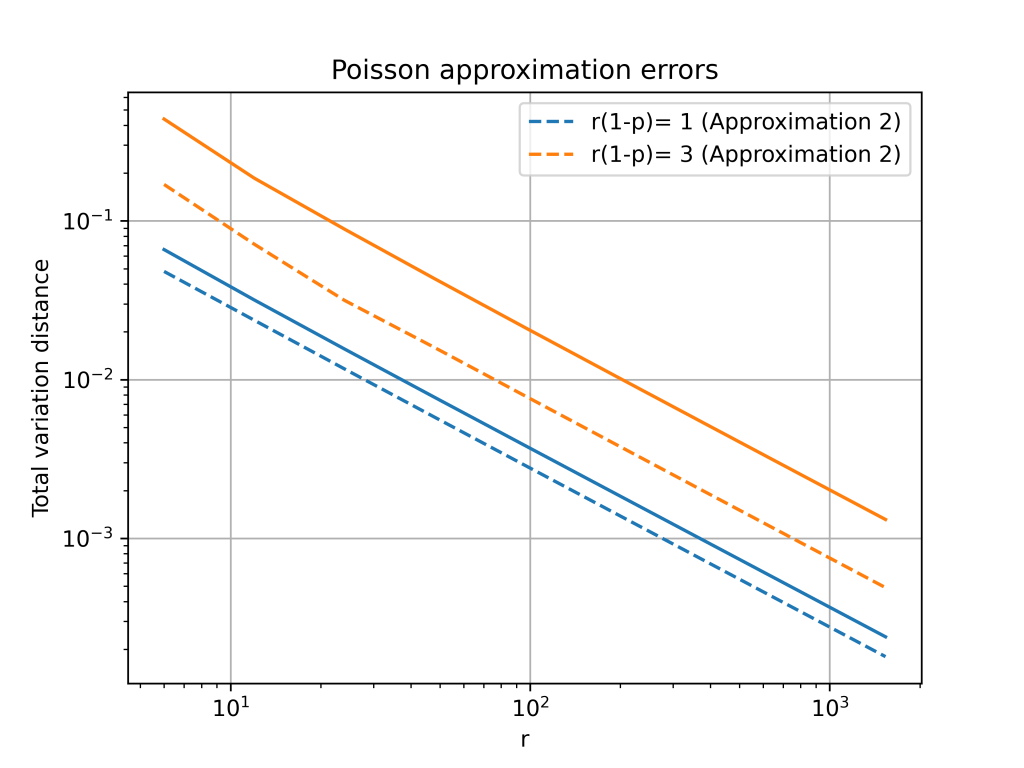
Second order accurate approximation
It is possible to further improve the Poisson approximation by using a Gram–Charlier expansion. A Gram–Charlier approximation for the Poisson distribution is given in this paper.1 The approximation is

where 


The Gram–Charlier expansion is considerably more accurate than either Poisson approximation. The errors are on the order of 

- The approximation is given in equation (4) of the paper and is stated in terms of the CDF instead of the PMF. The equation also contains a small typo, it should say
instead of
. ↩︎
 . It is a u-shaped distribution. There are peaks at
. It is a u-shaped distribution. There are peaks at  and
and  and a dip in the middle. The figure below shows the probability distribution function for
and a dip in the middle. The figure below shows the probability distribution function for  .
.

 is distributed according to the discrete arcsine distribution with parameter
is distributed according to the discrete arcsine distribution with parameter  converges in distribution to the continuous arcsine distribution on
converges in distribution to the continuous arcsine distribution on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The continuous arcsine distribution has the probability density function
. The continuous arcsine distribution has the probability density function
 . It is called the arcsine distribution because the cumulative distribution function involves the arcsine function
. It is called the arcsine distribution because the cumulative distribution function involves the arcsine function
 . I was surprised when I was told this, and couldn’t find a reference. The rest of this blog post proves that the discrete arcsine distribution is an instance of the beta-binomial distribution.
. I was surprised when I was told this, and couldn’t find a reference. The rest of this blog post proves that the discrete arcsine distribution is an instance of the beta-binomial distribution.
 is the Beta-function. To show that the discrete arc sine distribution is an instance of the beta-binomial distribution we need that
is the Beta-function. To show that the discrete arc sine distribution is an instance of the beta-binomial distribution we need that  . That is
. That is ,
, . To prove the above equation, we can first do some simplifying to
. To prove the above equation, we can first do some simplifying to  . By definition
. By definition ,
, factorial if
factorial if  is a natural number. The Gamma function
is a natural number. The Gamma function 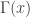 also satisfies the property
also satisfies the property 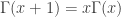 . Using this repeatedly gives
. Using this repeatedly gives

 is the double factorial. The same reasoning gives
is the double factorial. The same reasoning gives

 is also equal to the above final expression. Recall
is also equal to the above final expression. Recall
 (and hence
(and hence  ). To see why this last claim holds, note that
). To see why this last claim holds, note that
 as claimed.
as claimed. samples to estimate
samples to estimate  , the volume of an
, the volume of an 

 .
. . That is the distribution
. That is the distribution  is an
is an  . The conditional target distribution is
. The conditional target distribution is  the uniform distribution on the
the uniform distribution on the  . Here
. Here  is the Kullback-Liebler divergence between
is the Kullback-Liebler divergence between  . Kullback-Liebler divergence is defined as integral. Specifically
. Kullback-Liebler divergence is defined as integral. Specifically 
 to be the distribution of the norm squared under
to be the distribution of the norm squared under  , then
, then  and likewise for
and likewise for  . By the rotational symmetry of
. By the rotational symmetry of 
 and
and ![r \in [0,1]](https://s0.wp.com/latex.php?latex=r+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)

 . This means that
. This means that  . The distribution
. The distribution  , then
, then  is a scaled chi-squared variable. The shape parameter of
is a scaled chi-squared variable. The shape parameter of  . The density for
. The density for 


 we get that for large
we get that for large  .
.
 but an unknown rate
but an unknown rate ![\rho \in [0,1]](https://s0.wp.com/latex.php?latex=%5Crho+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The rate
. The rate  is given a
is given a  prior. That is the prior distribution of
prior. That is the prior distribution of 
 is a normalizing constant. The model can thus be written as
is a normalizing constant. The model can thus be written as


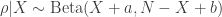 .
. . To calculate the distribution of
. To calculate the distribution of 


 for
for 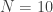 and a number of different values of
and a number of different values of  and
and  . You can see that, especially for small value of
. You can see that, especially for small value of 
