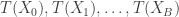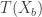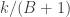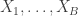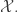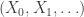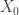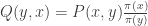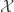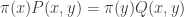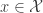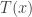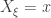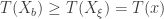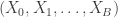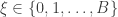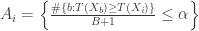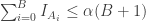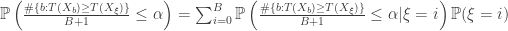A blog about statistics, mathematics and other things I have been thinking about.
MCMC for hypothesis testing
A Monte Carlo significance test of the null hypothesis requires creating independent samples . The idea is if and independently are i.i.d. from , then for any test statistic , the rank of among is uniformly distributed on . This means that if is one of the largest values of , then we can reject the hypothesis at the significance level .
The advantage of Monte Carlo significance tests is that we do not need an analytic expression for the distribution of under . By generating the i.i.d. samples , we are making an empirical distribution that approximates the theoretical distribution. However, sometimes sampling is just as intractable as theoretically studying the distribution of . Often approximate samples based on Markov chain Monte Carlo (MCMC) are used instead. However, these samples are not independent and may not be sampling from the true distribution. This means that a test using MCMC may not be statistically valid
In the 1989 paper Generalized Monte Carlo significance tests, Besag and Clifford propose two methods that solve this exact problem. Their two methods can be used in the same settings where MCMC is used but they are statistically valid and correctly control the Type 1 error. In this post, I will describe just one of the methods – the serial test.
Background on Markov chains
To describe the serial test we will need to introduce some notation. Let denote a transition matrix for a Markov chain on a discrete state space A Markov chain with transition matrix thus satisfies,
Suppose that the transition matrix has a stationary distribution . This means that if is a Markov chain with transition matrix and is distributed according to , then is also distributed according to . This implies that all are distributed according to .
We can construct a new transition matrix from and by . The transition matrix is called the reversal of . This is because for all and in , . That is the chance of drawing from and then transitioning to according to is equal to the chance of drawing from and then transitioning to according to
The new transition matrix also allows us to reverse longer runs of the Markov chain. Fix and let be a Markov chain with transition matrix and initial distribution . Also let be a Markov chain with transition matrix and initial distribution , then
,
where means equal in distribution.
The serial test
Suppose we want to test the hypothesis where is our observed data and is some distribution on . To conduct the serial test, we need to construct a Markov chain for which is a stationary distribution. We then also need to construct the reversal described above. There are many possible ways to construct such as the Metropolis-Hastings algorithm.
We also need a test statistic. This is a function which we will use to detect outliers. This function is the same function we would use in a regular Monte Carlo test. Namely, we want to reject the null hypothesis when is much larger than we would expect under .
The serial test then proceeds as follows. First we pick uniformly in and set . We then generate as a Markov chain with transition matrix that starts at . Likewise we generate as a Markov chain that starts from .
We then apply to each of and count the number of such that . If there are such , then the reported p-value of our test is .
We will now show that this test produces a valid p-value. That is, when , the probability that is less than is at most . In symbols,
Under the null hypothesis , is equal in distribution to generating from and using the transition matrix to go from to .
Thus, under the null hypothesis, the distribution of does not depend on . The entire procedure is equivalent to generating a Markov chain with initial distribution and transition matrix , and then choosing independently of . This is enough to show that the serial method produces valid p-values. The idea is that since the distribution of does not depend on and is uniformly distributed on , the probability that is in the top proportion of should be at most . This is proved more formally below.
For each , let be the event that is in the top proportion of . That is,
.
Let be the indicator function for the event . Since at must values of can be in the top fraction of , we have that
,
Therefor, by linearity of expectations,
By the law of total probability we have,
,
Since is uniform on , is for all . Furthermore, by independence of and , we have
.
Thus, by our previous bound,
.
Applications
In the original paper by Besag and Clifford, the authors discuss how this procedure can be used to perform goodness-of-fit tests. They construct Markov chains that can test the Rasch model or the Ising model. More broadly the method can be used to tests goodness-of-fit tests for any exponential family by using the Markov chains developed by Diaconis and Sturmfels.
A similar method has also been applied more recently to detect Gerrymandering. In this setting, the null hypothesis is the uniform distribution on all valid redistrictings of a state and the test statistics measure the political advantage of a given districting.