Monte Carlo integration
John Cook recently wrote a cautionary blog post about using Monte Carlo to estimate the volume of a high-dimensional ball. He points out that if  are independent and uniformly distributed on the interval
are independent and uniformly distributed on the interval ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) then
then

where  is the volume of an
is the volume of an  -dimensional ball with radius one. This observation means that we can use Monte Carlo to estimate .
-dimensional ball with radius one. This observation means that we can use Monte Carlo to estimate .
To do this we repeatedly sample vectors  with
with  uniform on and
uniform on and  ranging from
ranging from  to
to  . Next, we count the proportion of vectors
. Next, we count the proportion of vectors  with
with  . Specifically, if
. Specifically, if  is equal to one when and equal to zero otherwise, then by the law of large numbers
is equal to one when and equal to zero otherwise, then by the law of large numbers

Which implies

This method of approximating a volume or integral by sampling and counting is called Monte Carlo integration and is a powerful general tool in scientific computing.
The problem with Monte Carlo integration
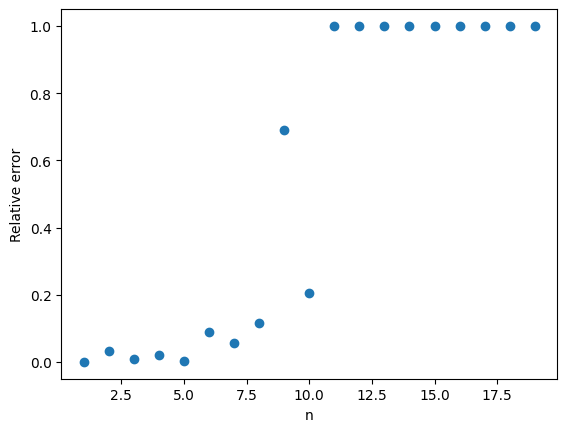
As pointed out by John, Monte Carlo integration does not work very well in this example. The plot below shows a large difference between the true value of with ranging from to 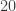 and the Monte Carlo approximation with
and the Monte Carlo approximation with  .
.
The problem is that is very small and the probability  is even smaller! For example when
is even smaller! For example when  ,
,  . This means that in our one thousand samples we only expect two or three occurrences of the event
. This means that in our one thousand samples we only expect two or three occurrences of the event  . As a result our estimate has a high variance.
. As a result our estimate has a high variance.
The results get even worse as increases. The probability does to zero faster than exponentially. Even with a large value of , our estimate will be zero. Since  , the relative error in the approximation is 100%.
, the relative error in the approximation is 100%.
Importance sampling
Monte Carlo can still be used to approximate . Instead of using plain Monte Carlo, we can use a variance reduction technique called importance sampling (IS). Instead of sampling the points  from the uniform distribution on , we can instead sample the from some other distribution called a proposal distribution. The proposal distribution should be chosen so that that the event
from the uniform distribution on , we can instead sample the from some other distribution called a proposal distribution. The proposal distribution should be chosen so that that the event  becomes more likely.
becomes more likely.
In importance sampling, we need to correct for the fact that we are using a new distribution instead of the uniform distribution. Instead of the counting the number of times  , we give weights to each of samples and then add up the weights.
, we give weights to each of samples and then add up the weights.
If  is the density of the uniform distribution on (the target distribution) and
is the density of the uniform distribution on (the target distribution) and  is the density of the proposal distribution, then the IS Monte Carlo estimate of is
is the density of the proposal distribution, then the IS Monte Carlo estimate of is

where as before is one if  and is zero otherwise. As long as
and is zero otherwise. As long as 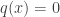 implies
implies  , the IS Monte Carlo estimate will be an unbiased estimate of . More importantly, a good choice of the proposal distribution can drastically reduce the variance of the IS estimate compared to the plain Monte Carlo estimate.
, the IS Monte Carlo estimate will be an unbiased estimate of . More importantly, a good choice of the proposal distribution can drastically reduce the variance of the IS estimate compared to the plain Monte Carlo estimate.
In this example, a good choice of proposal distribution is the normal distribution with mean  and variance
and variance  . Under this proposal distribution, the expected value of
. Under this proposal distribution, the expected value of  is one and so the event is much more likely.
is one and so the event is much more likely.
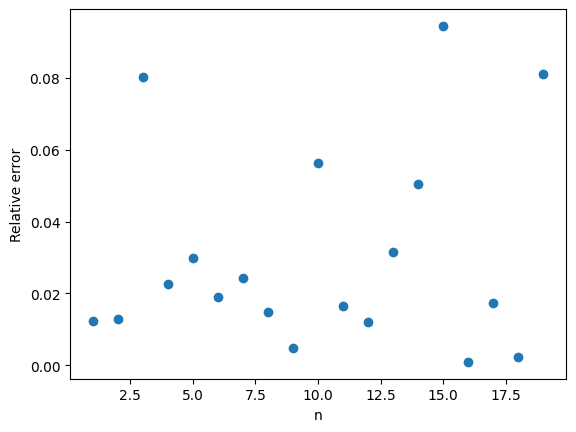
Here are the IS Monte Carlo estimates with again and ranging from to . The results speak for themselves.
The relative error is typically less than 10%. A big improvement over the 100% relative error of plain Monte Carlo.
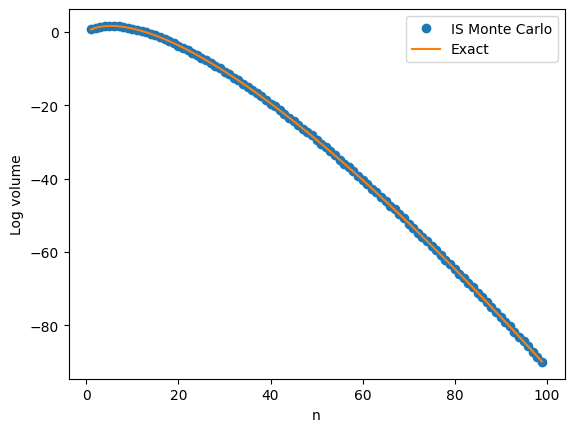
The next plot shows a close agreement between and the IS Monte Carlo approximation on the log scale with going all the way up to 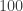 .
.
Notes
- There are exact formulas for (available on Wikipedia). I used these to compare the approximations and compute relative errors. There are related problems where no formulas exist and Monte Carlo integration is one of the only ways to get an approximate answer.
- The post by John Cook also talks about why the central limit theorem can’t be used to approximate . I initially thought a technique called large deviations could be used to approximate but again this does not directly apply. I was happy to discover that importance sampling worked so well!
More sampling posts



One thought on “Monte Carlo integration in high dimensions”