The singular value decomposition (SVD) is a powerful matrix decomposition. It is used all the time in statistics and numerical linear algebra. The SVD is at the heart of the principal component analysis, it demonstrates what’s going on in ridge regression and it is one way to construct the Moore-Penrose inverse of a matrix. For more SVD love, see the tweets below.
In this post I’ll define the SVD and prove that it always exists. At the end we’ll look at some pictures to better understand what’s going on.
Definition
Let  be a
be a 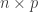 matrix. We will define the singular value decomposition first in the case
matrix. We will define the singular value decomposition first in the case  . The SVD consists of three matrix
. The SVD consists of three matrix  and
and 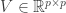 such that
such that  . The matrix
. The matrix  is required to be diagonal with non-negative diagonal entries
is required to be diagonal with non-negative diagonal entries  . These numbers are called the singular values of . The matrices
. These numbers are called the singular values of . The matrices  and
and  are required to orthogonal matrices so that
are required to orthogonal matrices so that  , the
, the 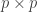 identity matrix. Note that since is square we also have
identity matrix. Note that since is square we also have 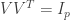 however we won’t have
however we won’t have 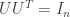 unless
unless 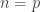 .
.
In the case when  , we can define the SVD of in terms of the SVD of
, we can define the SVD of in terms of the SVD of  . Let
. Let  and
and  be the SVD of so that
be the SVD of so that 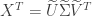 . The SVD of is then given by transposing both sides of this equation giving
. The SVD of is then given by transposing both sides of this equation giving  and
and 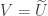 .
.
Construction
The SVD of a matrix can be found by iteratively solving an optimisation problem. We will first describe an iterative procedure that produces matrices and . We will then verify that  and satisfy the defining properties of the SVD.
and satisfy the defining properties of the SVD.
We will construct the matrices and one column at a time and we will construct the diagonal matrix one entry at a time. To construct the first columns and entries, recall that the matrix is really a linear function from 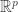 to
to  given by
given by 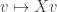 . We can thus define the operator norm of via
. We can thus define the operator norm of via

where  represents the Euclidean norm of
represents the Euclidean norm of  and
and  is the Euclidean norm of
is the Euclidean norm of 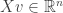 . The set of vectors
. The set of vectors  is a compact set and the function
is a compact set and the function  is continuous. Thus, the supremum used to define
is continuous. Thus, the supremum used to define 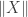 is achieved at some vector
is achieved at some vector  . Define
. Define 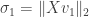 . If
. If  , then define
, then define 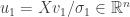 . If
. If 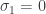 , then define
, then define  to be an arbitrary vector in with
to be an arbitrary vector in with 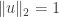 . To summarise we have
. To summarise we have
We have now started to fill in our SVD. The number  is the first singular value of and the vectors
is the first singular value of and the vectors 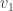 and will be the first columns of the matrices and respectively.
and will be the first columns of the matrices and respectively.
Now suppose that we have found the first  singular values
singular values  and the first columns of and . If
and the first columns of and . If  , then we are done. Otherwise we repeat a similar process.
, then we are done. Otherwise we repeat a similar process.
Let  and
and  be the first columns of and . The vectors split into two subspaces. These subspaces are
be the first columns of and . The vectors split into two subspaces. These subspaces are 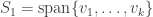 and
and 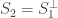 , the orthogonal compliment of
, the orthogonal compliment of 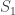 . By restricting to
. By restricting to  we get a new linear map
we get a new linear map  . Like before, the operator norm of
. Like before, the operator norm of  is defined to be
is defined to be
 .
.
Since  we must have
we must have

The set 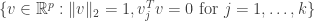 is a compact set and thus there exists a vector
is a compact set and thus there exists a vector 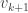 such that
such that  . As before define
. As before define 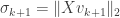 and
and  if
if  . If
. If  , then define
, then define 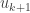 to be any vector in
to be any vector in 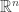 that is orthogonal to
that is orthogonal to  .
.
This process repeats until eventually and we have produced matrices and . In the next section, we will argue that these three matrices satisfy the properties of the SVD.
Correctness
The defining properties of the SVD were given at the start of this post. We will see that most of the properties follow immediately from the construction but one of them requires a bit more analysis. Let ![U = [u_1,\ldots,u_p]](https://s0.wp.com/latex.php?latex=U+%3D+%5Bu_1%2C%5Cldots%2Cu_p%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,  and
and ![V= [v_1,\ldots,v_p]](https://s0.wp.com/latex.php?latex=V%3D+%5Bv_1%2C%5Cldots%2Cv_p%5D&bg=ffffff&fg=333333&s=0&c=20201002) be the output from the above construction.
be the output from the above construction.
First note that by construction  are orthogonal since we always had
are orthogonal since we always had 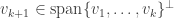 . It follows that the matrix is orthogonal and so
. It follows that the matrix is orthogonal and so 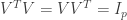 .
.
The matrix is diagonal by construction. Furthermore, we have that 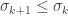 for every . This is because both
for every . This is because both  and
and  were defined as maximum value of over different subsets of . The subset for contained the subset for and thus
were defined as maximum value of over different subsets of . The subset for contained the subset for and thus  .
.
We’ll next verify that . Since is orthogonal, the vectors  form an orthonormal basis for . It thus suffices to check that
form an orthonormal basis for . It thus suffices to check that 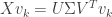 for
for 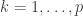 . Again by the orthogonality of we have that
. Again by the orthogonality of we have that 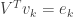 , the
, the  standard basis vector. Thus,
standard basis vector. Thus,

Above, we used that was a diagonal matrix and that 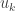 is the column of . If
is the column of . If  , then
, then  by definition. If
by definition. If  , then
, then  and so
and so 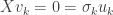 also. Thus, in either case,
also. Thus, in either case, 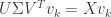 and so
and so  .
.
The last property we need to verify is that is orthogonal. Note that this isn’t obvious. At each stage of the process, we made sure that . However, in the case that 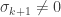 , we simply defined . It is not clear why this would imply that is orthogonal to .
, we simply defined . It is not clear why this would imply that is orthogonal to .
It turns out that a geometric argument is needed to show this. The idea is that if was not orthogonal to 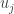 for some
for some 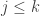 , then
, then 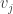 couldn’t have been the value that maximises .
couldn’t have been the value that maximises .
Let  and be two columns of with
and be two columns of with  and
and 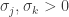 . We wish to show that
. We wish to show that 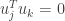 . To show this we will use the fact that and
. To show this we will use the fact that and 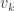 are orthonormal and perform “polar-interpolation“. That is, for
are orthonormal and perform “polar-interpolation“. That is, for ![\lambda \in [0,1]](https://s0.wp.com/latex.php?latex=%5Clambda+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , define
, define

Since 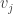 and are orthogonal, we have that
and are orthogonal, we have that

Furthermore  is orthogonal to
is orthogonal to 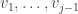 . Thus, by definition of ,
. Thus, by definition of ,

By the linearity of and the definitions of  ,
,
 .
.
Since  and
and  , we have
, we have

Rearranging and dividing by  gives,
gives,
 for all
for all ![\lambda \in (0,1]](https://s0.wp.com/latex.php?latex=%5Clambda+%5Cin+%280%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Taking 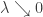 gives
gives 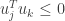 . Performing the same polar interpolation with
. Performing the same polar interpolation with  shows that
shows that 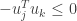 and hence .
and hence .
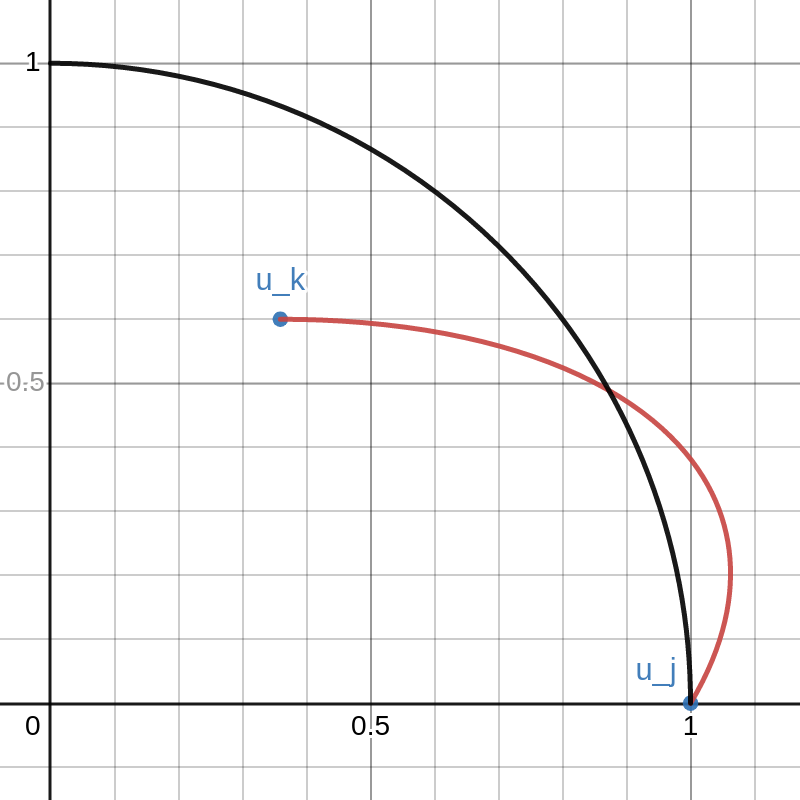
We have thus proved that is orthogonal. This proof is pretty “slick” but it isn’t very illuminating. To better demonstrate the concept, I made an interactive Desmos graph that you can access here.
This graph shows example vectors  . The vector is fixed at
. The vector is fixed at 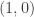 and a quarter circle of radius
and a quarter circle of radius  is drawn. Any vectors
is drawn. Any vectors  that are outside this circle have
that are outside this circle have 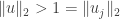 .
.
The vector can be moved around inside this quarter circle. This can be done either cby licking and dragging on the point or changing that values of  and
and  on the left. The red curve is the path of
on the left. The red curve is the path of
 .
.
As  goes from
goes from  to , the path travels from to .
to , the path travels from to .
Note that there is a portion of the red curve near that is outside the black circle. This corresponds to a small value of 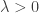 that results in
that results in 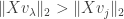 contradicting the definition of . By moving the point around in the plot you can see that this always happens unless lies exactly on the y-axis. That is, unless is orthogonal to .
contradicting the definition of . By moving the point around in the plot you can see that this always happens unless lies exactly on the y-axis. That is, unless is orthogonal to .





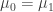



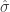




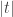


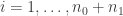


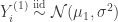
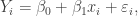


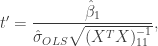

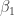



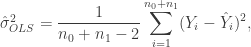
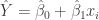
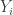

![[1,x_i]](https://s0.wp.com/latex.php?latex=%5B1%2Cx_i%5D&bg=ffffff&fg=333333&s=0&c=20201002)



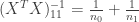




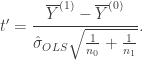


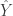


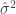

 requires creating independent samples
requires creating independent samples  . The idea is if
. The idea is if  are i.i.d. from
are i.i.d. from  , then for any test statistic
, then for any test statistic  , the rank of
, the rank of  among
among 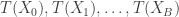 is uniformly distributed on
is uniformly distributed on  . This means that if
. This means that if 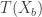 , then we can reject the hypothesis
, then we can reject the hypothesis  at the significance level
at the significance level 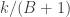 .
. 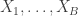 is just as intractable as theoretically studying the distribution of
is just as intractable as theoretically studying the distribution of  denote a transition matrix for a Markov chain on a discrete state space
denote a transition matrix for a Markov chain on a discrete state space 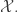 A Markov chain with transition matrix
A Markov chain with transition matrix 
 . This means that if
. This means that if 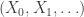 is a Markov chain with transition matrix
is a Markov chain with transition matrix 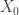 is distributed according to
is distributed according to  is also distributed according to
is also distributed according to  are distributed according to
are distributed according to  from
from 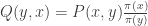 . The transition matrix
. The transition matrix  and
and  in
in 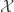 ,
, 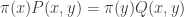 . That is the chance of drawing
. That is the chance of drawing 
 and let
and let  be a Markov chain with transition matrix
be a Markov chain with transition matrix  be a Markov chain with transition matrix
be a Markov chain with transition matrix  ,
, means equal in distribution.
means equal in distribution. 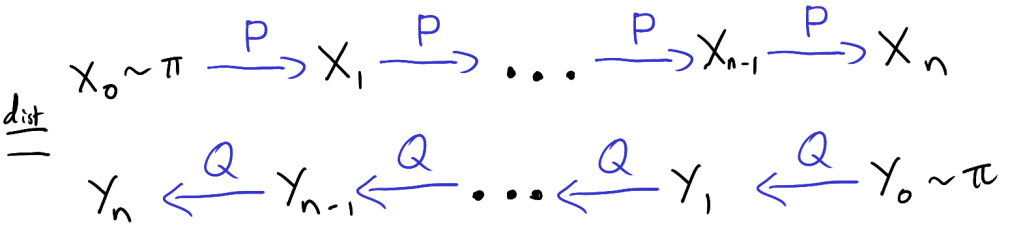
 where
where 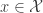 is our observed data and
is our observed data and  which we will use to detect outliers. This function is the same function we would use in a regular Monte Carlo test. Namely, we want to reject the null hypothesis when
which we will use to detect outliers. This function is the same function we would use in a regular Monte Carlo test. Namely, we want to reject the null hypothesis when 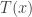 is much larger than we would expect under
is much larger than we would expect under  uniformly in
uniformly in  and set
and set 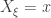 . We then generate
. We then generate  as a Markov chain with transition matrix
as a Markov chain with transition matrix  as a Markov chain that starts from
as a Markov chain that starts from 
 and count the number of
and count the number of  such that
such that 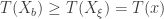 . If there are
. If there are  is at most
is at most 
 .
. 
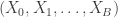 does not depend on
does not depend on  with initial distribution
with initial distribution 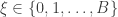 independently of
independently of  . This is enough to show that the serial method produces valid p-values. The idea is that since the distribution of
. This is enough to show that the serial method produces valid p-values. The idea is that since the distribution of  is in the top
is in the top  , let
, let  be the event that
be the event that  is in the top
is in the top  . That is,
. That is,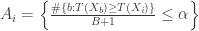 .
. be the indicator function for the event
be the indicator function for the event  values of
values of  can be in the top
can be in the top 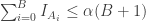 ,
,
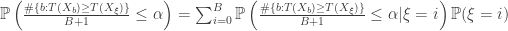 ,
, ,
,  is
is 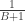 for all
for all  .
. .
. . She explains that when an equation says two things are equal we very rarely mean that they are exactly the same thing. What we really mean is that the two things are the same in some ways even though they may be different in others.
. She explains that when an equation says two things are equal we very rarely mean that they are exactly the same thing. What we really mean is that the two things are the same in some ways even though they may be different in others.  . This is such a familiar statement that you might really think that
. This is such a familiar statement that you might really think that 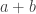 and
and  are the same thing. Indeed, if
are the same thing. Indeed, if  is the same as the number you get when you calculate
is the same as the number you get when you calculate  . But calculating
. But calculating 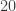 , then calculating
, then calculating 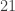 but calculating
but calculating  is the same as
is the same as 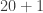 .
.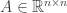 and any pair of vectors
and any pair of vectors  , if
, if 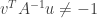 , then
, then 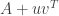 is invertible and
is invertible and
 , any matrix
, any matrix  of size
of size  that satisfy the above condition.
that satisfy the above condition. 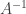 and now want the inverse of
and now want the inverse of 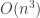 computations since we have to invert a
computations since we have to invert a  matrix. On the right hand side, we only need to compute a small number of matrix-vector products and then add two matrices together. This bring the computational cost down to
matrix. On the right hand side, we only need to compute a small number of matrix-vector products and then add two matrices together. This bring the computational cost down to 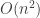 .
.  comes from a distribution of the form:
comes from a distribution of the form: ,
,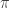 is a vector and
is a vector and 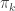 is equal to the probability that
is equal to the probability that  are the parameters for the
are the parameters for the  ,
, . We can see that the log-likelihood is of the form log-sum-exp. Calculating a log-sum-exp can cause issues with numerical stability. For instance if
. We can see that the log-likelihood is of the form log-sum-exp. Calculating a log-sum-exp can cause issues with numerical stability. For instance if 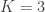 and
and  , for all
, for all  , then the final answer is simply
, then the final answer is simply  . However, as soon as we try to calculate
. However, as soon as we try to calculate  on a computer, we’ll be in trouble.
on a computer, we’ll be in trouble.  ,
, .
. we can more safely compute the log-sum-exp expression. For instance, in the
we can more safely compute the log-sum-exp expression. For instance, in the 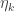 . This (hopefully) makes each of the terms
. This (hopefully) makes each of the terms  a reasonable size and avoids any numerical issues.
a reasonable size and avoids any numerical issues. 
 .
. ![f:[a,b] \to \mathbb{R}](https://s0.wp.com/latex.php?latex=f%3A%5Ba%2Cb%5D+%5Cto+%5Cmathbb%7BR%7D&bg=ffffff&fg=333333&s=0&c=20201002) “wiggles”. In this post, I want to motivate the definition of total variation by talking about elevation in marathon running.
“wiggles”. In this post, I want to motivate the definition of total variation by talking about elevation in marathon running. 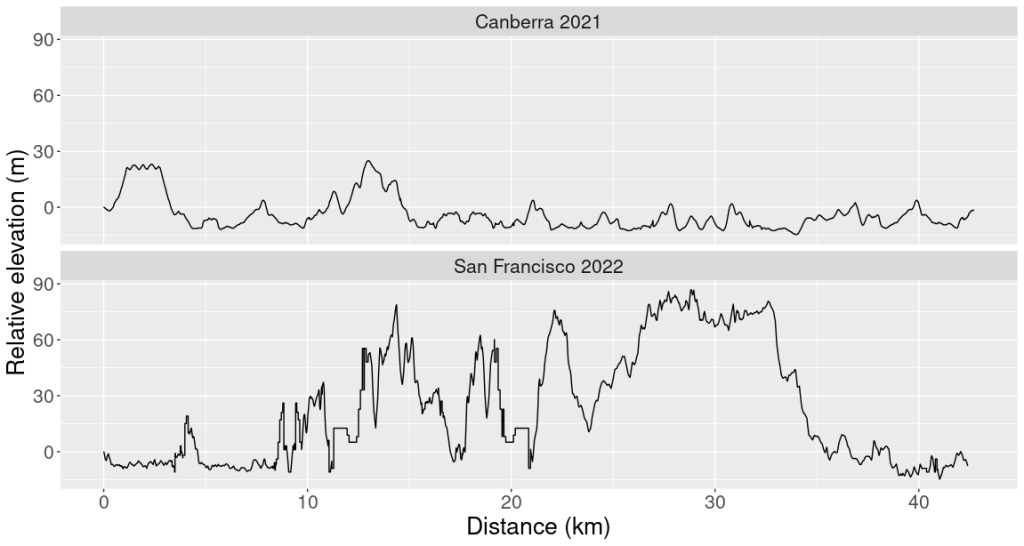





 might not be made up of straight lines. But we can approximate
might not be made up of straight lines. But we can approximate ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) . A partition of
. A partition of 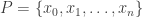 such that:
such that:  .
.  is a collection of increasing points in
is a collection of increasing points in 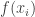 and
and 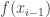 . In symbols, we define
. In symbols, we define  (the variation over
(the variation over 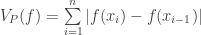 .
.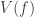 and define it as:
and define it as:![V(f) = \sup\{V_P(f) : P \text{ is a partition of } [a,b]\}](https://s0.wp.com/latex.php?latex=V%28f%29+%3D+%5Csup%5C%7BV_P%28f%29+%3A+P+%5Ctext%7B+is+a+partition+of+%7D+%5Ba%2Cb%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
.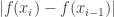 with the positive part
with the positive part 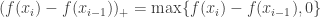 . This means that only the lines that slope upwards will count towards the wiggliness score. Lines that slope downwards get a wiggliness score of zero.
. This means that only the lines that slope upwards will count towards the wiggliness score. Lines that slope downwards get a wiggliness score of zero.


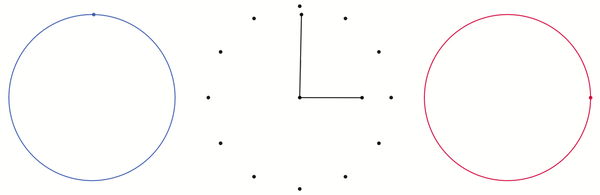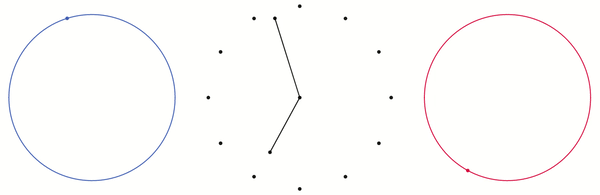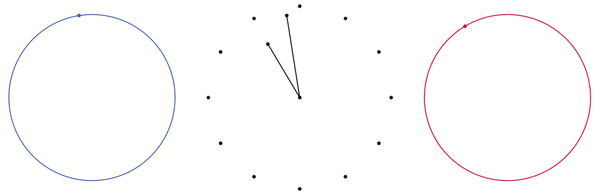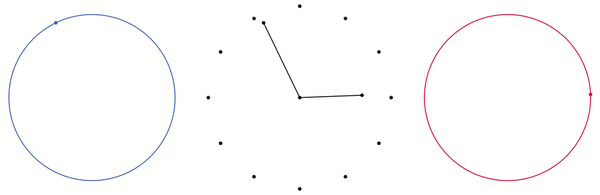

 in the two dimensional plane. Likewise, if we have a point
in the two dimensional plane. Likewise, if we have a point  and a point
and a point  on two different circles, then we can produce a point
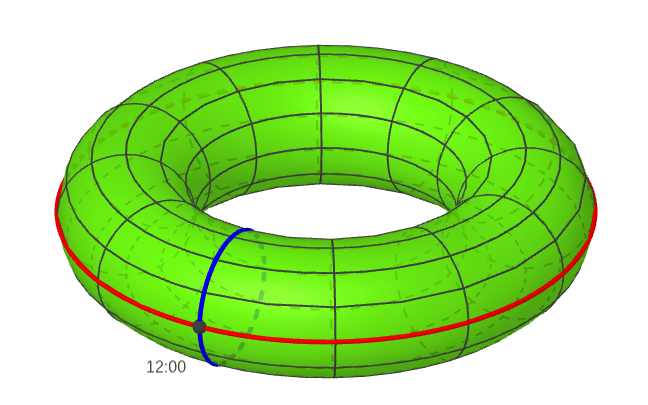
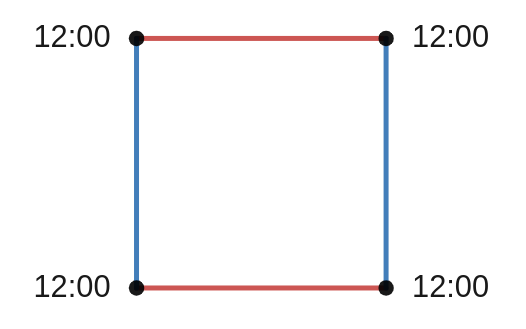
on two different circles, then we can produce a point  on the torus. Both of these concepts are illustrated below. I have added two circles to the torus which are analogous to the x and y axes of the plane. The blue and red points on the blue and red circle produce the black point on the torus.
on the torus. Both of these concepts are illustrated below. I have added two circles to the torus which are analogous to the x and y axes of the plane. The blue and red points on the blue and red circle produce the black point on the torus.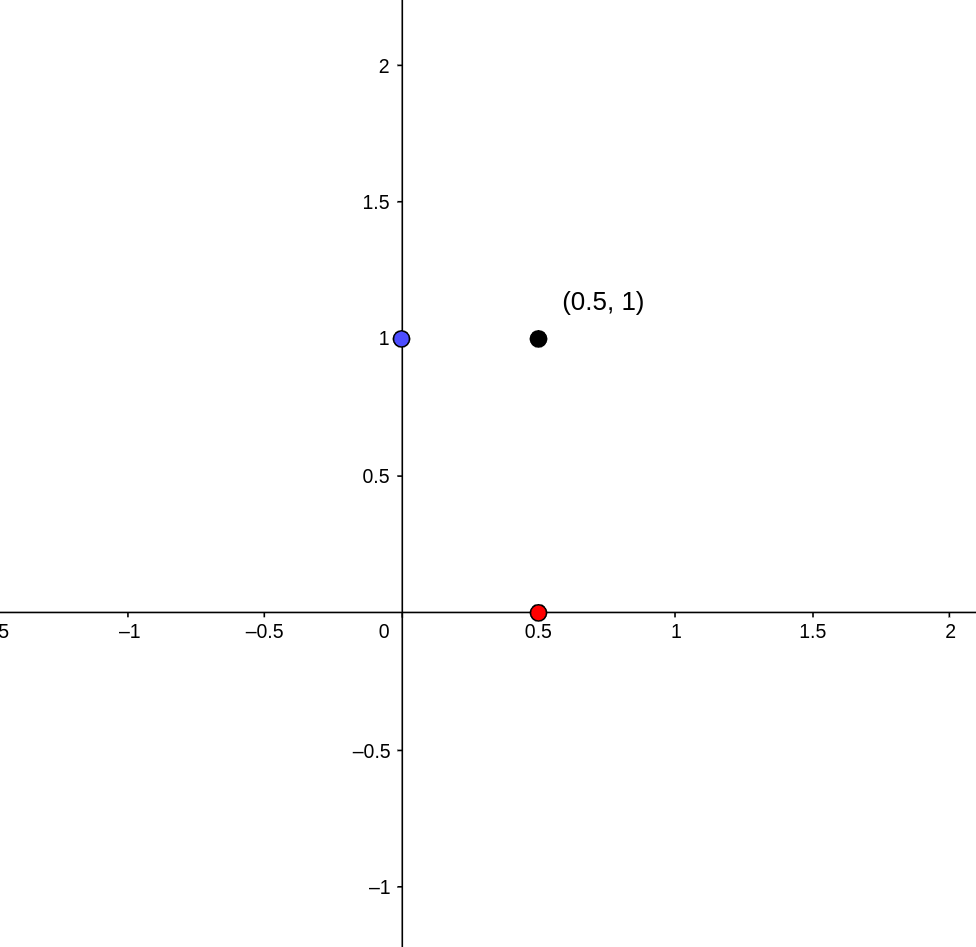




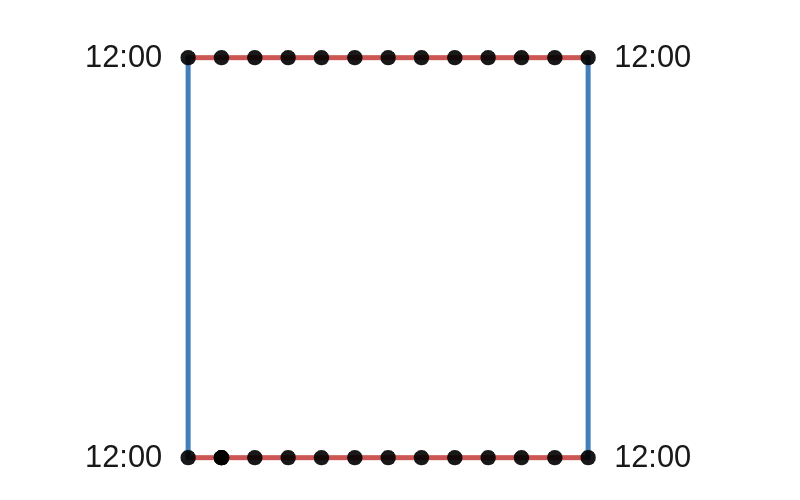
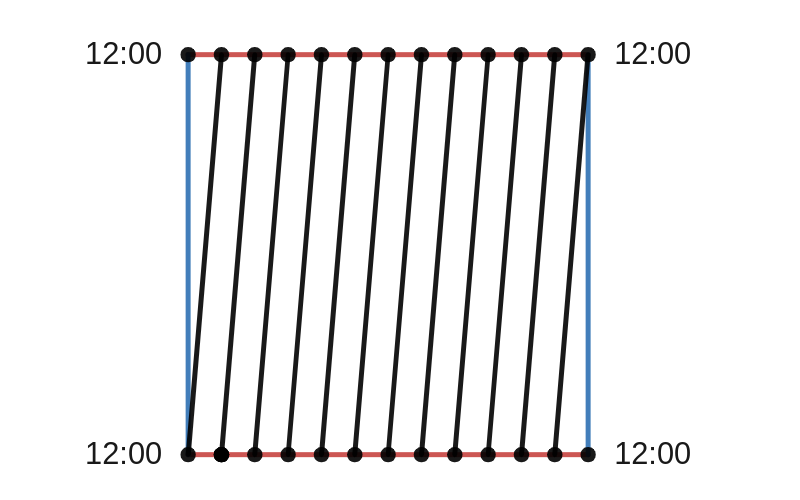

 be a normally distributed random vector with mean
be a normally distributed random vector with mean 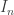 . Given a vector
. Given a vector  , the non-central chi-squared distribution with
, the non-central chi-squared distribution with  is the distribution of the quantity
is the distribution of the quantity
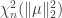 . As this notation suggests, the distribution of
. As this notation suggests, the distribution of 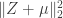 depends only on
depends only on 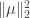 , the norm of
, the norm of  . The first few times I heard this fact, I had no idea why it would be true (and even found it a little
. The first few times I heard this fact, I had no idea why it would be true (and even found it a little  such that
such that 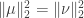 . We wish to show that if
. We wish to show that if  , then
, then  .
. have the same norm there exists an orthogonal matrix
have the same norm there exists an orthogonal matrix  such that
such that  . Since
. Since  . Furthermore, since
. Furthermore, since  . This is because, for all
. This is because, for all 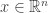 ,
,
 .
. have the same distribution, we can conclude that
have the same distribution, we can conclude that  has the same distribution as
has the same distribution as  . Since
. Since  , we are done.
, we are done. depends only on the norm of the vector
depends only on the norm of the vector 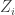 and then return
and then return  . But for large values of
. But for large values of  where
where 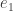 is the vector with a
is the vector with a 
 follows the regular chi-squared distribution with
follows the regular chi-squared distribution with  degrees of freedom and is independent of
degrees of freedom and is independent of  . The regular chi-squared distribution is a special case of the gamma distribution and can be effectively sampled with rejection sampling for large shape parameter (see
. The regular chi-squared distribution is a special case of the gamma distribution and can be effectively sampled with rejection sampling for large shape parameter (see 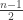 , so for large values of
, so for large values of 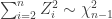 . Finally to get a sample from
. Finally to get a sample from  .
. 
 and an equivalence relation
and an equivalence relation 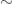 on
on  . That is, the set
. That is, the set  . The contradictory nature of this statement is illustrated in the picture below
. The contradictory nature of this statement is illustrated in the picture below 
 means that in some sense there are more regions than crosses.
means that in some sense there are more regions than crosses. be two sets. We say that
be two sets. We say that  if there exists a bijection function
if there exists a bijection function  . We can think of the function
. We can think of the function  which means
which means 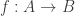 .
.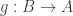 .
. such that
such that  . We simply take
. We simply take  to be the range of
to be the range of  the set of all function
the set of all function  . We can think of each elements
. We can think of each elements  as an infinite sequence of zeros and ones stretching off in both directions. For example
as an infinite sequence of zeros and ones stretching off in both directions. For example .
. . For instance, the two sequences below look the same but when we make
. For instance, the two sequences below look the same but when we make 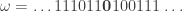 ,
,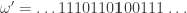 .
. if and only if there exists
if and only if there exists 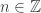 such that
such that  for all
for all  . That is, if we shift the sequence
. That is, if we shift the sequence  by
by 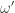 . We will use
. We will use ![[\omega]](https://s0.wp.com/latex.php?latex=%5B%5Comega%5D&bg=ffffff&fg=333333&s=0&c=20201002) to denote the equivalence class of
to denote the equivalence class of  , one for each integer
, one for each integer  . A probabilist or statistician would think of
. A probabilist or statistician would think of 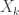 as reporting the result of one of infinitely many independent coin tosses. Normally to make this formal we would have to first define a
as reporting the result of one of infinitely many independent coin tosses. Normally to make this formal we would have to first define a 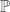 defined on all subsets of
defined on all subsets of  .
.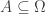 in a way so that the events
in a way so that the events 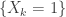 are all independent and have probability
are all independent and have probability  . It’s important to note that this is a true countably additive probability and we can apply all our familiar probability results to
. It’s important to note that this is a true countably additive probability and we can apply all our familiar probability results to 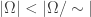 .
.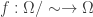 be any function. To show that
be any function. To show that  given by
given by ![g(\omega)=f([\omega])](https://s0.wp.com/latex.php?latex=g%28%5Comega%29%3Df%28%5B%5Comega%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) . That is,
. That is,  first maps
first maps 
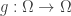 is almost surely constant with respect to
is almost surely constant with respect to  such that
such that 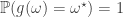 . Each equivalence class
. Each equivalence class  .
.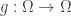 is almost surely constant. To do this we will introduce a third function
is almost surely constant. To do this we will introduce a third function 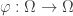 . The map
. The map 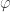 is simply the shift map and is given by
is simply the shift map and is given by  . Note that
. Note that  are in the same equivalence class for every
are in the same equivalence class for every 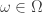 . Thus, the map
. Thus, the map  . That is
. That is  , then
, then 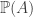 equals
equals 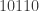 appears at some point in
appears at some point in  . Likewise if
. Likewise if  . The general claim that all
. The general claim that all 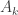 by
by  . Since
. Since  . Thus,
. Thus,  or
or  given by
given by  . Note that for every
. Note that for every  . This is because if
. This is because if  , then
, then 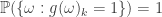 , by definition of
, by definition of 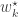 . Likewise if
. Likewise if  , then
, then  and hence
and hence 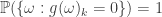 . Thus, in both cases,
. Thus, in both cases,  .
. .
.
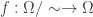 . Does this mean we have proved
. Does this mean we have proved  ? Technically no. We have proved the negation of
? Technically no. We have proved the negation of 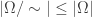 which does not imply
which does not imply  . To argue that
. To argue that  that is injective. Surprising this is possible and not too difficult. The idea is to find a map
that is injective. Surprising this is possible and not too difficult. The idea is to find a map  implies that
implies that 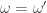 . This can be done by somehow encoding in
. This can be done by somehow encoding in  where the centre of
where the centre of 
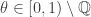 and define
and define  for some
for some  .
. is Borel measurable. To get the result for binary sequences we have to restrict to
is Borel measurable. To get the result for binary sequences we have to restrict to 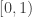 and use the binary expansion of
and use the binary expansion of 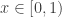 to define a function
to define a function  . Solvay’s paper is available here
. Solvay’s paper is available here 
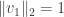 .
. .
.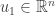 with
with  and
and  .
.